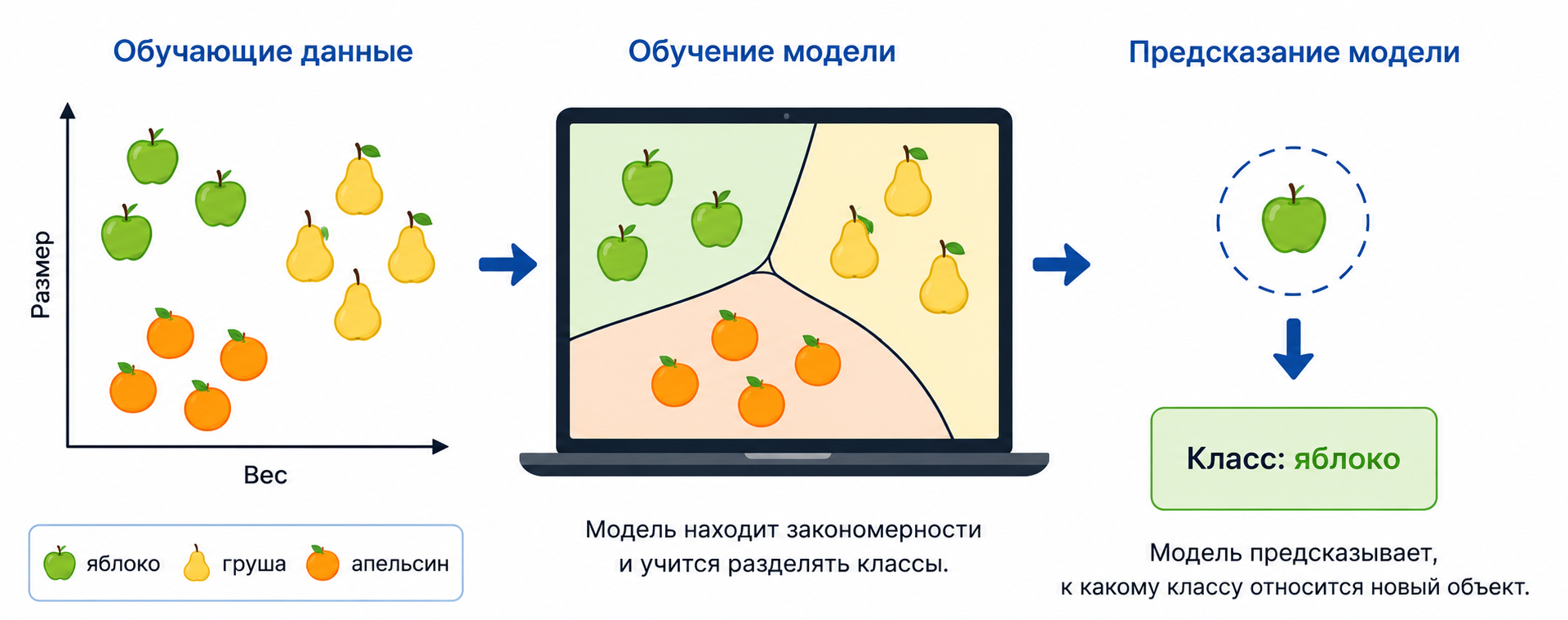
Классификация
Классификация используется, когда нужно отнести объект к одному из заранее известных классов.
Например, модель может учиться отличать яблоки, груши и апельсины по признакам: размеру, весу, цвету и форме.
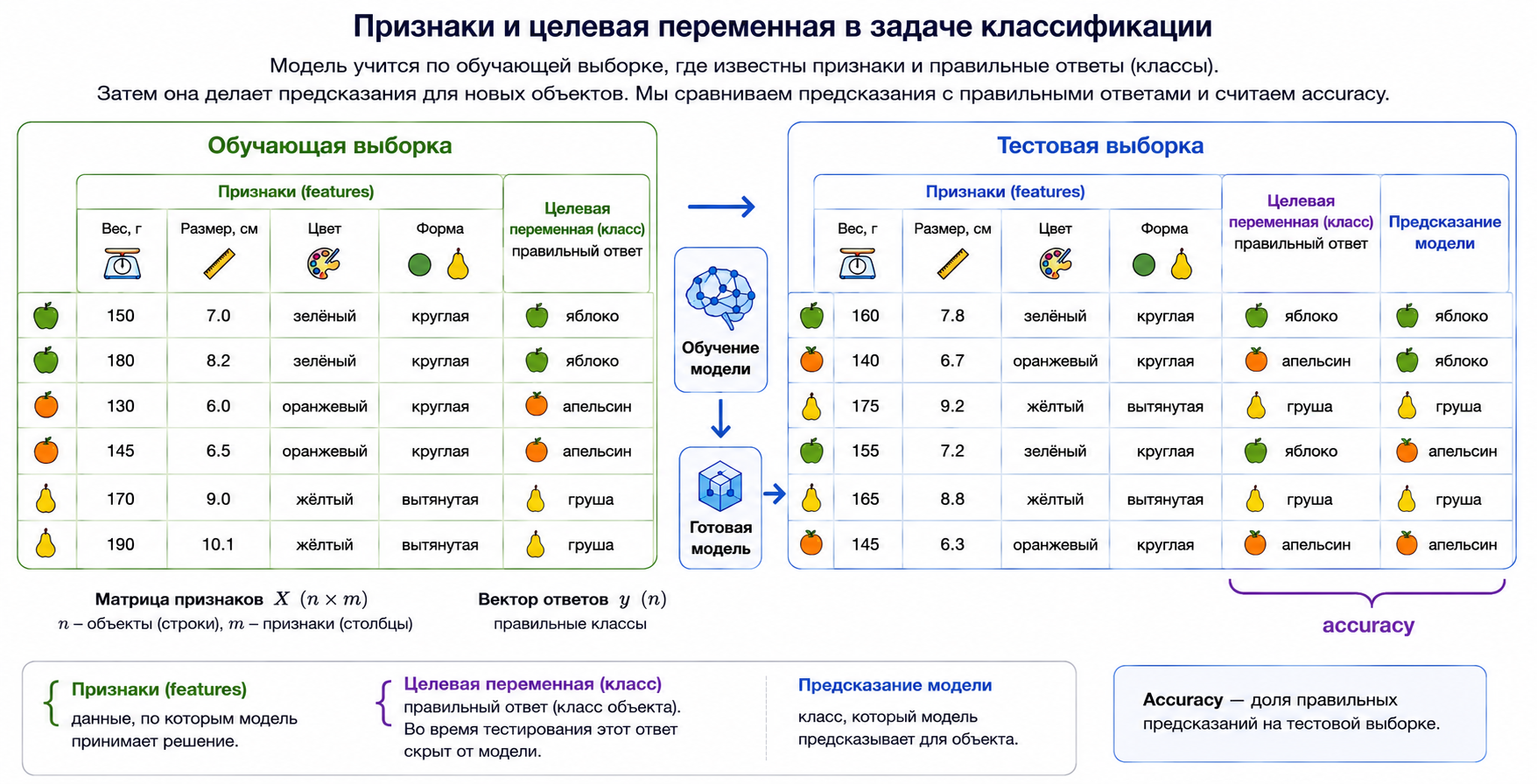
Признаки и целевая переменная
Заголовок раздела «Признаки и целевая переменная»Признаки (features) — это данные, по которым модель принимает решение.
Целевая переменная (target) — это то, что модель должна предсказать.
В задаче классификации целевая переменная принимает значения из конечного набора категорий: яблоко, груша, апельсин.
В программе признаки обычно записываются в матрицу X, а целевая переменная — в вектор y.
Метки классов
Заголовок раздела «Метки классов»В классификации значения целевой переменной называются классами или метками классов.
Например:
яблокогрушаапельсин
являются тремя классами задачи классификации фруктов.
Обучение и проверка
Заголовок раздела «Обучение и проверка»Чтобы понять, действительно ли модель научилась решать задачу, данные обычно делят на две части:
- обучающую выборку — на ней модель учится;
- тестовую выборку — на ней проверяется качество модели.
Такой подход называется TrainTestSplit. Он помогает проверить модель на данных, которые она не видела во время обучения.
Оценка качества
Заголовок раздела «Оценка качества»Самая простая метрика для классификации — Accuracy. Она показывает долю правильных ответов.
Например, Accuracy = 0.90 означает, что модель правильно ответила примерно в 90% случаев.
Для более сложных задач используют и другие метрики: Precision, Recall, F1 и матрицу ошибок. Они особенно важны, если классы встречаются неравномерно.