Оценка качества модели
После обучения модель можно использовать для предсказаний на новых данных. Но сразу возникает важный вопрос: насколько точны её ответы?
Чтобы это проверить, нужно подать на вход модели данные, для которых правильные ответы уже известны. А затем сравнить предсказания модели с правильными ответами.
Но есть проблема: если проверять модель на тех же данных, на которых она обучалась, результат будет неверным. Модель просто «вспомнит» правильные ответы, а не научится решать новые задачи.
Поэтому в машинном обучении поступают следующим образом. Все данные заранее делят на две части:
- обучающая выборка (
train) — на ней модель учится. Обычно это 70–80% всех данных; - тестовая выборка (
test) — на ней проверяют качество. Модель не видит эти данные во время обучения.
Разбиение на эти части выполняется случайно: часть объектов попадает в train, часть — в test.
TrainTestSplit
Заголовок раздела «TrainTestSplit»Когда признаки уже находятся в матрице X, а целевые значения — в массиве y, для разбиения
можно использовать метод Validation.TrainTestSplit.
var (Xtrain, Xtest, ytrain, ytest) := Validation.TrainTestSplit(X, y, testRatio := 0.25, seed := 42);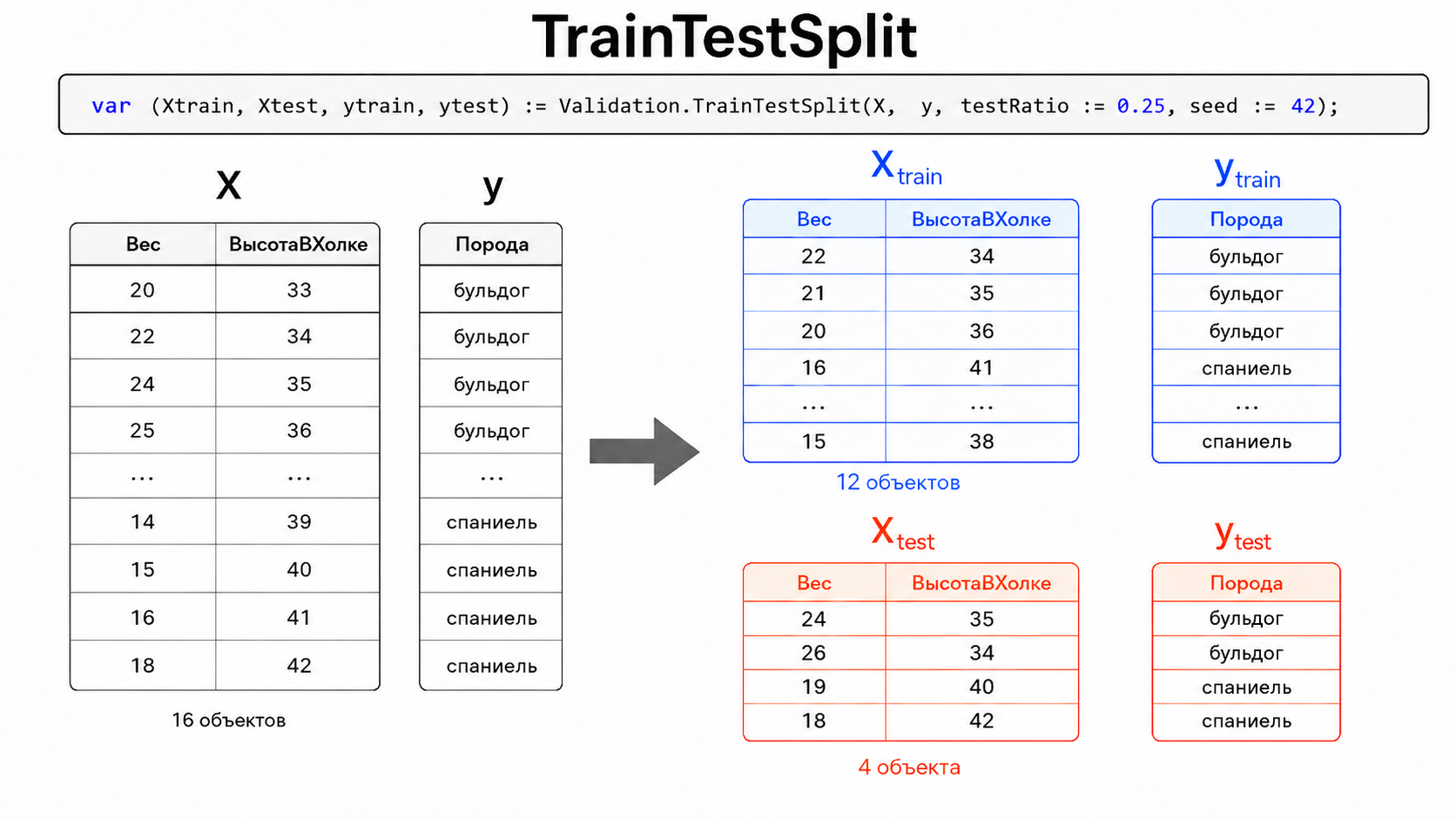
В результате разбиения отдельно получаются признаки для обучения (Xtrain), признаки для проверки (Xtest), правильные ответы для обучения (ytrain) и правильные ответы для проверки (ytest).
Validation.TrainTestSplit — низкоуровневая универсальная операция. Она не анализирует смысл y, а только согласованно делит X и y, чтобы строки признаков и соответствующие им ответы не перемешались между собой.
Параметр testRatio задаёт долю данных, которая попадёт в тестовую выборку. Например, 0.25 означает,
что 25% данных будут использованы для проверки, а 75% — для обучения модели.
Параметр seed задаёт начальное значение для генератора случайных чисел.
Это гарантирует, что разбиение данных будет одинаковым при каждом запуске. Если этот параметр не указать,
то при каждом запуске мы будем получать разные разбиения.
В этом примере мы сначала готовим признаки и целевую переменную, затем делим данные на обучающую и тестовую части.
uses MLABC;
begin var df := DataFrame.FromCsvText(''' Вес,ВысотаВХолке,Порода 20,33,бульдог 17,43,спаниель 16,41,спаниель 25,36,бульдог 26,34,бульдог 21,35,бульдог 24,35,бульдог 20,36,бульдог 14,39,спаниель 15,40,спаниель 19,39,бульдог 18,42,спаниель 22,34,бульдог 15,38,спаниель 19,40,спаниель 16,40,спаниель ''');
var X := df.ToMatrix(['Вес', 'ВысотаВХолке']); var target := df.EncodeTarget('Порода'); var y := target.Labels;
var (Xtrain, Xtest, ytrain, ytest) := Validation.TrainTestSplit(X, y, testRatio := 0.25, seed := 42);
var model := new KNNClassifier(3); model.Fit(Xtrain, ytrain);
var ypred := model.Predict(Xtest); var acc := Metrics.Accuracy(ytest, ypred);
Println('Accuracy:', acc);end.После обучения модель делает предсказания для тестовой выборки:
var ypred := model.Predict(Xtest);Затем Metrics.Accuracy сравнивает предсказанные классы ypred с правильными ответами ytest. Точность показывает, какая доля объектов из тестовой выборки была классифицирована правильно.
Вывод программы:
Accuracy: 0.75Это означает, что модель правильно определила породу для 75% объектов из тестовой выборки. Другими словами, из четырёх тестовых примеров три были классифицированы правильно.
Важная деталь: целевой столбец кодируется до разбиения. Так классы получают единую кодировку для всей задачи.
DataFrame-разбиение
Заголовок раздела «DataFrame-разбиение»У DataFrame тоже есть разбиение:
var (trainDf, testDf) := df.TrainTestSplit(0.2, seed := 42);Такой вариант удобен, когда дальше используется DataPipeline: конвейер сам обучает преобразования на trainDf, а потом применяет их к testDf.
Для ручных примеров без конвейера часто проще сначала получить X и y, а затем использовать Validation.TrainTestSplit.
StratifiedTrainTestSplit
Заголовок раздела «StratifiedTrainTestSplit»Для классификации часто важно сохранить соотношение классов в обучающей и тестовой выборках.
Например, если в исходных данных 50% объектов класса A и 50% объектов класса B, желательно, чтобы примерно такое же соотношение сохранилось и после разбиения.
Такое разбиение называется стратифицированным.
В ML PascalABC.NET стратифицированное разбиение находится на уровне DataFrame и Dataset, а не в Validation. Причина простая: для стратификации нужно понимать, какой столбец является целевым и какие в нём классы. Эта информация есть в таблице или датасете, но её уже нет в сырой матрице X и массиве y.
var (trainDf, testDf) := df.StratifiedTrainTestSplit('Порода', testRatio := 0.2, seed := 42);Этот вариант особенно полезен, если классы несбалансированы: например, объектов одного класса много, а другого мало.
Полный пример со стратифицированным разбиением удобнее рассматривать вместе с DataPipeline: после разбиения нужно одинаково подготовить обучающую и тестовую части.
Что использовать
Заголовок раздела «Что использовать»| Задача | Что использовать |
|---|---|
Уже подготовлены X и y | Validation.TrainTestSplit |
| Ручной учебный пример без pipeline | обычно Validation.TrainTestSplit после получения X и y |
Таблица DataFrame с целевым столбцом | DataFrame.StratifiedTrainTestSplit |
| Встроенный датасет с метаданными | Dataset.StratifiedTrainTestSplit |
| Кросс-валидация для классификации | Validation.StratifiedKFold |
Типичные ошибки
Заголовок раздела «Типичные ошибки»Обучение и проверка на одних данных
Заголовок раздела «Обучение и проверка на одних данных»model.Fit(X, y);var pred := model.Predict(X); // плохо для честной оценкиТакая оценка обычно завышает качество модели, потому что модель проверяется на данных, которые уже видела.
Разбиение без seed
Заголовок раздела «Разбиение без seed»var (Xtrain, Xtest, ytrain, ytest) := Validation.TrainTestSplit(X, y, testRatio := 0.2);Каждый запуск может дать другое разбиение. Из-за этого результаты могут немного меняться, и сравнивать модели становится сложнее.
Обычное разбиение при сильном дисбалансе классов
Заголовок раздела «Обычное разбиение при сильном дисбалансе классов»Если в столбце целевых значений присутствует редкий класс, он может случайно не попасть в тестовую часть.
Для табличных данных в такой ситуации лучше использовать стратифицированное разбиение на уровне DataFrame:
var (trainDf, testDf) := df.StratifiedTrainTestSplit('Порода', testRatio := 0.2, seed := 42);Оно сохраняет соотношение классов в обучающей и тестовой выборках.