Обработка пропусков
В реальных данных часто встречаются пропуски: кто-то не указал возраст, для товара не заполнена цена, датчик не передал измерение, часть строк пришла из неполного файла.
Для обычного просмотра таблицы это не всегда критично, но модели машинного обучения обычно ожидают полную числовую таблицу. Если в признаках есть пустые значения, модель может не обучиться или дать некорректный результат. Поэтому перед обучением пропуски нужно обработать.
Подробнее о том, как найти и удалить пропуски в таблице, см. раздел Пропущенные данные. Здесь речь идёт именно о подготовке данных перед машинным обучением.
Основные способы обработки
Заголовок раздела «Основные способы обработки»С пропусками обычно делают одно из следующих действий:
- удаляют строки с пропусками;
- заменяют числовые пропуски средним значением;
- заменяют числовые пропуски медианой;
- заменяют пропуски заранее выбранной константой.
Удаление строк подходит не всегда: если данных мало, можно потерять важные примеры. Поэтому в задачах машинного обучения часто используют заполнение пропусков.
Imputer
Заголовок раздела «Imputer»Imputer — это преобразователь, который заполняет пропущенные значения по выбранному правилу.
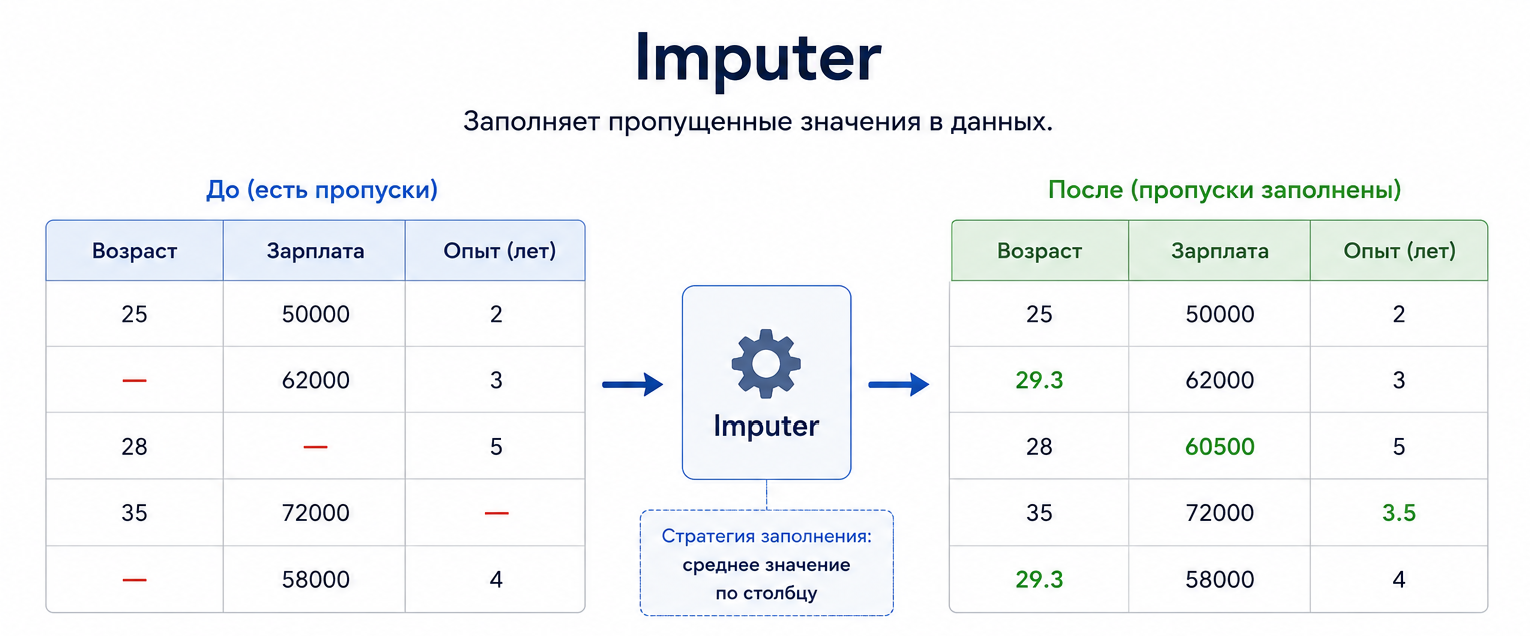
Идея такая:
Imputerсмотрит на данные и запоминает, чем заменять пропуски.- Затем он применяет это правило и возвращает новую таблицу без пропусков в выбранных столбцах.
По умолчанию Imputer заполняет числовые пропуски средним значением по столбцу.
Другие варианты:
new Imputer(['Возраст']) // среднее значениеnew Imputer(ImputeStrategy.isMedian, ['Возраст']) // медианаnew Imputer(0, ['Возраст']) // константаnew Imputer('Не указан', ['Отдел']) // строковая константаСтратегии isMean и isMedian работают с числовыми столбцами. Константа подходит и для числовых, и для строковых, и для логических столбцов, если значение имеет подходящий тип.
uses MLABC;
begin var df := DataFrame.FromCsvText(''' Имя,Возраст,Зарплата Анна,28,90000 Борис,,85000 Вера,31, Глеб,35,110000 ''');
var imputer := new Imputer(['Возраст', 'Зарплата']); var filled := imputer.FitTransform(df);
filled.Print;end.В этом примере Imputer заполняет пропуски в столбцах Возраст и Зарплата средними значениями:
- для
Возраст: среднее от28,31и35; - для
Зарплата: среднее от90000,85000и110000.
Исходная таблица df не изменяется, результат сохраняется в новую переменную filled.
Вывод программы:
Имя Возраст Зарплата Анна 28.00 90000.00Борис 31.33 85000.00 Вера 31.00 95000.00 Глеб 35.00 110000.00Два этапа: Fit и Transform
Заголовок раздела «Два этапа: Fit и Transform»В примере выше используется короткая запись FitTransform: она сразу вычисляет значения для заполнения и применяет их к таблице.
То же самое можно записать в два шага:
var imputer := new Imputer(['Возраст', 'Зарплата']);
imputer.Fit(df);var filled := imputer.Transform(df);Fit вычисляет значения для замены пропусков. Transform применяет уже найденное правило и возвращает новую таблицу.
Позже, когда появится разбиение на обучающую и тестовую выборки, это разделение станет особенно важным: правило заполнения нужно будет вычислять по обучающим данным, а затем применять к другим данным. Это будет рассмотрено в разделе про TrainTestSplit.
Что выбрать
Заголовок раздела «Что выбрать»- Если пропусков очень мало, иногда достаточно удалить строки.
- Для числовых столбцов часто используют среднее или медиану.
- Для строковых и категориальных столбцов удобно использовать константу, например
'Не указан'. - Для машинного обучения лучше использовать
Imputer, чтобы одинаково обрабатывать исходные и новые данные.