Масштабирование признаков
В таблице признаки часто измеряются в разных единицах. Например, количество комнат — это числа от 1 до 5, площадь квартиры — десятки квадратных метров, а цена — миллионы рублей.
Для человека это нормально, но некоторые модели машинного обучения работают с числовыми расстояниями или градиентами. В таких моделях признак с большими числами может начать слишком сильно влиять на результат только из-за масштаба.
Масштабирование приводит числовые признаки к сопоставимому виду.
StandardScaler
Заголовок раздела «StandardScaler»StandardScaler — один из самых распространённых способов масштабирования.
Он преобразует каждый числовой признак так, чтобы:
- среднее значение стало близко к
0; - стандартное отклонение стало близко к
1.
Идея простая: из каждого значения вычитается среднее по столбцу, а затем результат делится на стандартное отклонение.
StandardScaler применяется к числовой матрице признаков, а не напрямую к DataFrame. Поэтому сначала нужно выбрать числовые столбцы и преобразовать их в Matrix с помощью ToMatrix.
uses MLABC;
begin var df := DataFrame.FromCsvText(''' Площадь,Цена,Комнат 40,6000000,1 55,8500000,2 70,11000000,2 90,15000000,3 120,21000000,4 ''');
var X := df.ToMatrix(['Площадь', 'Цена', 'Комнат']);
Println('До масштабирования:'); X.Print; Println;
var scaler := new StandardScaler; var Xscaled := scaler.FitTransform(X);
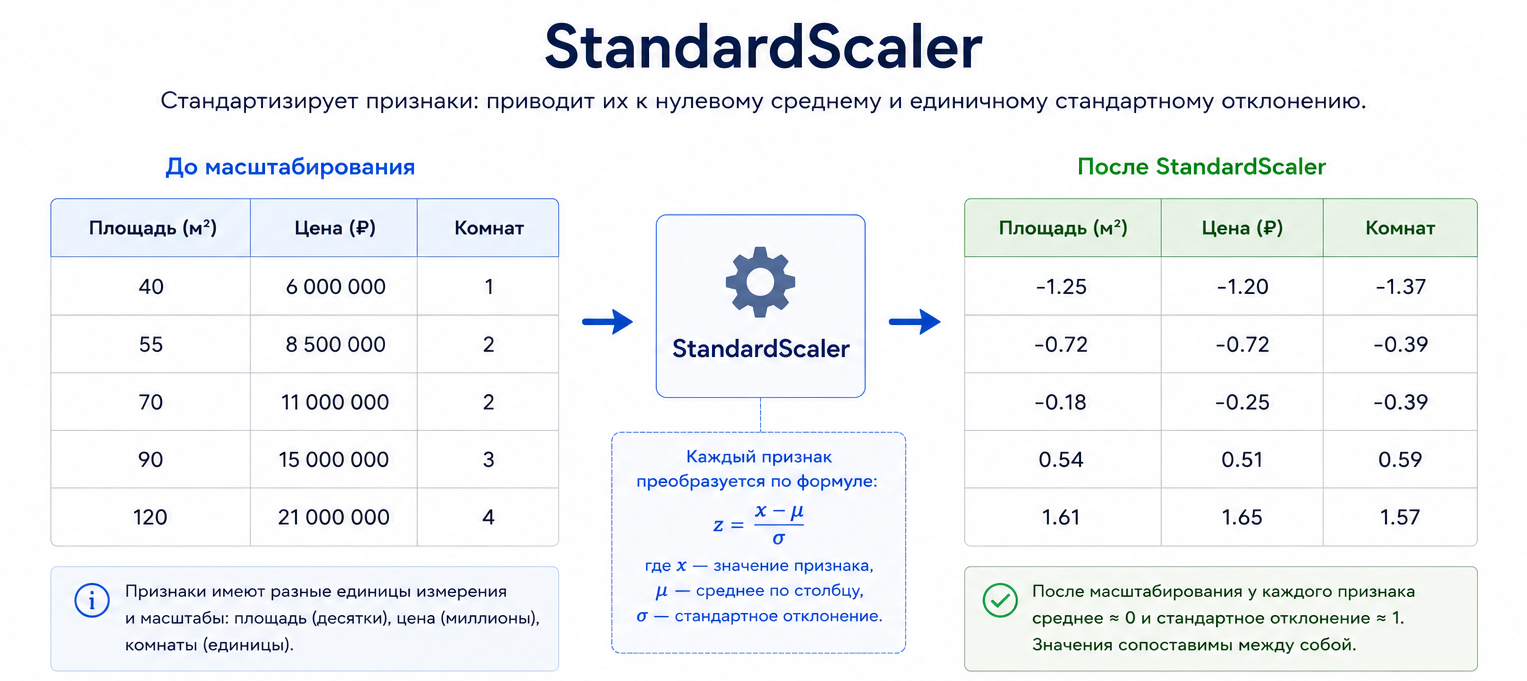
Println('После StandardScaler:'); Xscaled.Print;end.В строке df.ToMatrix(['Площадь', 'Цена', 'Комнат']) из таблицы берутся только числовые признаки. Именно матрица X затем передаётся в StandardScaler.
В исходных данных Цена измеряется миллионами, Площадь — десятками, а Комнат — маленькими целыми числами. После StandardScaler все три признака оказываются в сопоставимом масштабе.
Вывод программы:
До масштабирования: 40.00 6000000.00 1.00 55.00 8500000.00 2.00 70.00 11000000.00 2.00 90.00 15000000.00 3.00 120.00 21000000.00 4.00
После StandardScaler: -1.25 -1.20 -1.37 -0.72 -0.72 -0.39 -0.18 -0.25 -0.39 0.54 0.51 0.59 1.61 1.65 1.57После масштабирования значения в каждом столбце центрированы: если сложить числа в одном столбце, получится значение, близкое к 0.
FitTransform и Fit / Transform
Заголовок раздела «FitTransform и Fit / Transform»Короткая запись:
var Xscaled := scaler.FitTransform(X);Она сразу вычисляет параметры масштабирования и применяет их к матрице.
То же самое можно записать в два шага:
scaler.Fit(X);var Xscaled := scaler.Transform(X);Fit вычисляет средние значения и стандартные отклонения. Transform применяет уже найденные параметры.
Когда масштабирование важно
Заголовок раздела «Когда масштабирование важно»Масштабирование особенно важно для моделей, которые используют расстояния между объектами или чувствительны к размеру чисел:
KNNClassifier;KNNRegressor;LogisticRegression;- линейные модели.
Например, в KNN расстояние между объектами считается по признакам. Если один признак измеряется миллионами, а другой единицами, большой признак может почти полностью определить расстояние.
Когда масштабирование обычно не критично
Заголовок раздела «Когда масштабирование обычно не критично»Для деревьев решений масштабирование обычно не так важно:
DecisionTreeClassifier;DecisionTreeRegressor;RandomForest;GradientBoosting.
Деревья сравнивают значения внутри одного признака, поэтому разный масштаб между признаками обычно влияет меньше.
Другие способы
Заголовок раздела «Другие способы»В библиотеке есть и другие способы масштабирования, например MinMaxScaler и Normalizer. Но на первых шагах чаще всего достаточно понимать и использовать StandardScaler.