LogisticRegression
LogisticRegression — модель для задач классификации. Несмотря на слово «регрессия» в названии, она используется не для предсказания числа, а для выбора класса.
Обычно логистическую регрессию используют как одну из первых моделей: она простая, быстрая и хорошо показывает, насколько задача вообще решается линейной границей.
Что делает модель
Заголовок раздела «Что делает модель»Логистическая регрессия строит границу между классами.
Если у объекта два числовых признака, эту границу можно представить как прямую линию на плоскости. Например, если классифицировать собак по весу и высоте в холке, модель пытается провести прямую так, чтобы по одну сторону оказались объекты одного класса, а по другую — другого.
Если признаков больше двух, вместо прямой получается плоскость или гиперплоскость в многомерном пространстве признаков. Идея остаётся той же: модель делит пространство признаков на области.
Вероятность класса
Заголовок раздела «Вероятность класса»Логистическая регрессия не просто выбирает класс. Сначала она оценивает вероятность.
Для бинарной классификации результат можно понимать так:
- объект далеко по одну сторону от разделяющей прямой — модель уверена в первом классе;
- объект далеко по другую сторону — модель уверена во втором классе;
- объект близко к разделяющей прямой — вероятность близка к
50% / 50%.
Поэтому логистическая регрессия особенно удобна, когда важно не только получить ответ, но и понимать степень уверенности модели.
Когда использовать
Заголовок раздела «Когда использовать»LogisticRegression хорошо подходит, когда:
- нужна простая базовая модель для классификации;
- классы можно разделить примерно прямой линией, плоскостью или гиперплоскостью;
- признаки уже подготовлены и представлены числами;
- важно быстро получить первый результат.
Модель может работать хуже, если граница между классами сложная и сильно нелинейная.
Пример обучения
Заголовок раздела «Пример обучения»В примере ниже модель учится отличать бульдогов от спаниелей по двум числовым признакам: весу и высоте в холке.
У бульдогов обычно больше вес при небольшой высоте, а спаниели обычно выше и легче. Поэтому модель смотрит не на один признак отдельно, а на их сочетание.
uses MLABC, PlotML;
begin var df := DataFrame.FromCsvText(''' Вес,ВысотаВХолке,Порода 20,33,бульдог 22,34,бульдог 24,35,бульдог 25,36,бульдог 19,35,бульдог 21,35,бульдог 26,34,бульдог 20,36,бульдог 14,39,спаниель 15,40,спаниель 16,41,спаниель 18,42,спаниель 17,43,спаниель 15,38,спаниель 19,40,спаниель 16,40,спаниель ''');
var X := df.ToMatrix(['Вес', 'ВысотаВХолке']); var target := df.EncodeTarget('Порода'); var y := target.Labels; var classNames := target.Classes;
var model := new LogisticRegression; model.Fit(X, y);
var example := [20.0, 38.0]; var pred := model.PredictOne(example); var prob := model.PredictProbaOne(example);
Println('Предсказанная порода:', classNames[pred]); Println('Предсказанные вероятности:'); Println(classNames[0]:10, '-', prob[0]:0:2); Println(classNames[1]:10, '-', prob[1]:0:2);
Plot.XLabel := df.ColumnNames[0]; Plot.YLabel := df.ColumnNames[1]; Plot.Title := 'Бульдоги и спаниели';
Plot.Points(X.Col(0), X.Col(1), y); Plot.Points([example[0]], [example[1]], Colors.Black, size := 8);
var (A, B, C) := model.DecisionBoundary.Coefficients; Plot.Line(A, B, C);end.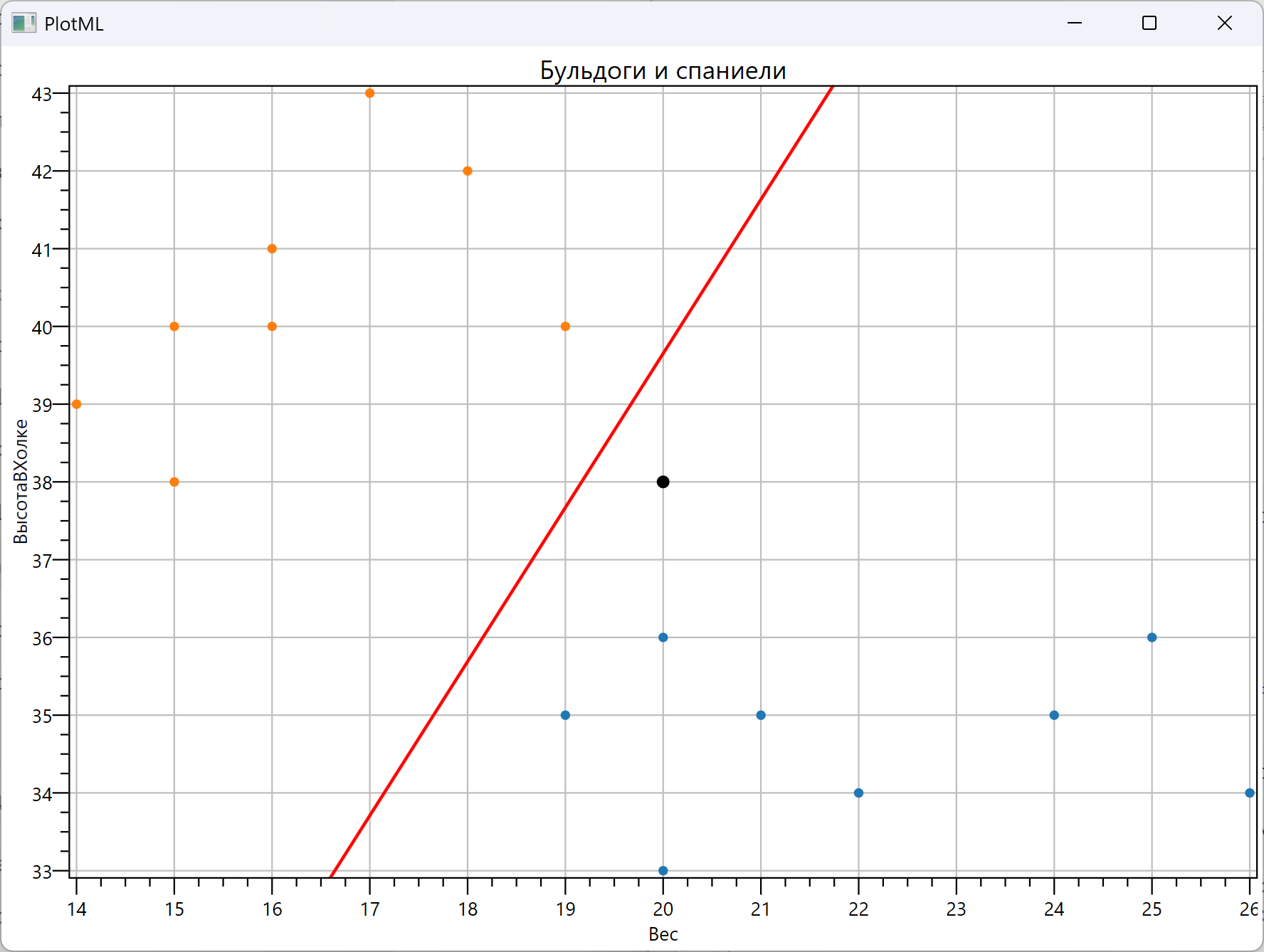
Здесь Вес и ВысотаВХолке — признаки, а Порода — целевая переменная. Метод EncodeTarget кодирует целевой столбец и возвращает запись EncodedTarget.
У неё есть два поля:
Labels— числовые метки классов для обучения модели;Classes— исходные названия классов в том же порядке.
Например, модель работает с числами 0 и 1, а target.Classes позволяет затем вывести понятные названия: бульдог или спаниель.
В таблице есть несколько пограничных примеров: некоторые бульдоги и спаниели имеют близкие значения веса и высоты. Поэтому модель должна построить разделяющую прямую, а не просто запомнить очевидное правило.
После обучения PredictOne получает признаки одной новой собаки: вес 20 кг и высоту в холке 38 см. Модель возвращает код предсказанного класса, а classNames из target.Classes переводит этот код обратно в название породы.
Метод PredictProbaOne возвращает вероятности классов для этого же объекта. Если точка находится близко к разделяющей прямой, вероятности будут ближе к 50% / 50%; если далеко от неё — модель будет увереннее.
В конце программа строит график. Цветные точки — обучающие данные, большая чёрная точка — новый объект, для которого предсказывается порода. Красная линия — разделяющая прямая, найденная логистической регрессией.
В реальных задачах качество модели проверяют отдельно: данные делят на обучающую и тестовую выборки с помощью TrainTestSplit, а затем считают метрики, например Accuracy.
Основные гиперпараметры
Заголовок раздела «Основные гиперпараметры»Гиперпараметры — это настройки, которые задаются до обучения модели.
В большинстве учебных примеров достаточно настроек по умолчанию:
var model := new LogisticRegression;Иногда можно изменить несколько основных гиперпараметров:
learningRate— скорость обучения. Слишком большое значение может мешать обучению, слишком маленькое — сделать обучение медленным.epochs— сколько раз модель проходит по данным во время обучения.lambda— сила регуляризации. Регуляризация помогает модели не слишком подстраиваться под обучающие данные.
Например:
var model := new LogisticRegression( learningRate := 0.005, epochs := 2000);- Простая и быстрая модель.
- Хорошо подходит как первая базовая модель.
- Даёт вероятностную оценку класса.
- Хорошо работает, если классы примерно линейно разделимы.
- Строит линейную границу, поэтому плохо описывает сложные нелинейные зависимости.
- Может быть чувствительна к масштабу признаков.
- Для сложных задач часто уступает деревьям решений, случайному лесу или градиентному бустингу.